四十分钟,把Linux操作系统,你知道的,不知道的,都问出来了。这些问题下来,如果你是电子信息专业的同学,那你能答多少呢?如果是计算机科学与技术或者是软件工程专业的同学,可能后边就废了。。。也可能不会问得那么偏。。
-
平台总线(Platform Bus): -
平台总线是计算机硬件体系结构中的一部分,它负责连接和协调不同的硬件组件,如中央处理器(CPU)、内存、输入/输出(I/O)设备等。 -
平台总线提供了标准的物理连接和通信协议,以便各个硬件组件之间可以相互通信和协作。 -
常见的平台总线包括系统总线(例如,PCI、PCI Express)、内存总线等。
-
-
平台设备(Platform Device): -
平台设备是指与计算机平台(硬件架构)相关的物理硬件设备,这些设备可以通过平台总线连接到计算机。 -
例如,图形处理器(GPU)、声卡、网卡、USB控制器等都属于平台设备。 -
平台设备通常由硬件制造商设计和制造,它们通过驱动程序与操作系统进行交互,以便在计算机上执行各种任务。
-
-
平台驱动(Platform Driver): -
平台驱动是一种软件组件,通常运行在操作系统内核或作为内核模块加载到操作系统中。 -
它们的主要任务是与平台设备进行通信和控制。这包括初始化设备、管理设备资源、接收和处理设备产生的中断、与设备进行数据传输等。 -
平台驱动通常由硬件制造商或社区开发,以确保平台设备可以与各种操作系统兼容。 -
操作系统会通过驱动程序提供的接口来与平台设备进行通信,从而实现对设备的控制和数据交换。
-
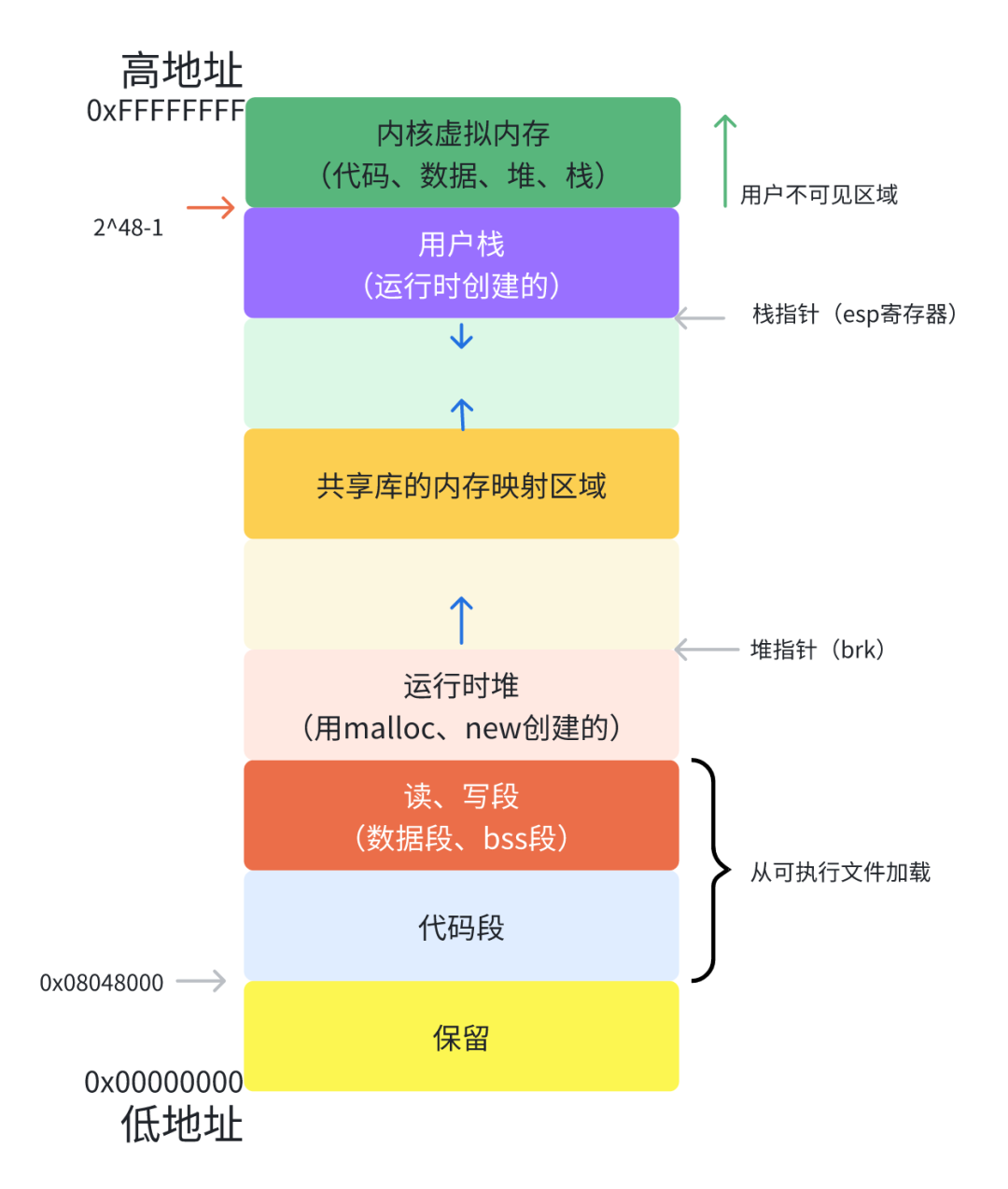
pmap命令可以显示进程的内存映射情况,包括虚拟地址范围、映射文件、权限等信息。可以通过指定进程ID(PID)来查看特定进程的内存映射。pmap -x <PID>-
代码区和数据区域:这些区域来自可执行文件,内核加载可执行文件时会将代码区和数据区域映射到进程的虚拟地址空间中。代码区通常是只读的,而数据区域可以读取和写入。内核确保不同进程的代码和数据区域不会互相干扰,通过使用虚拟内存技术将它们分隔开。 -
运行时堆区域:运行时堆区域的管理由内存分配函数(如 malloc)和内核共同完成。内核负责管理堆的虚拟地址范围,当进程需要分配内存时,内核将动态扩展堆的虚拟地址范围,确保不同进程之间的堆不会互相干扰。同时,内核还会跟踪已分配和已释放的内存块,以防止内存泄漏和重复释放。 -
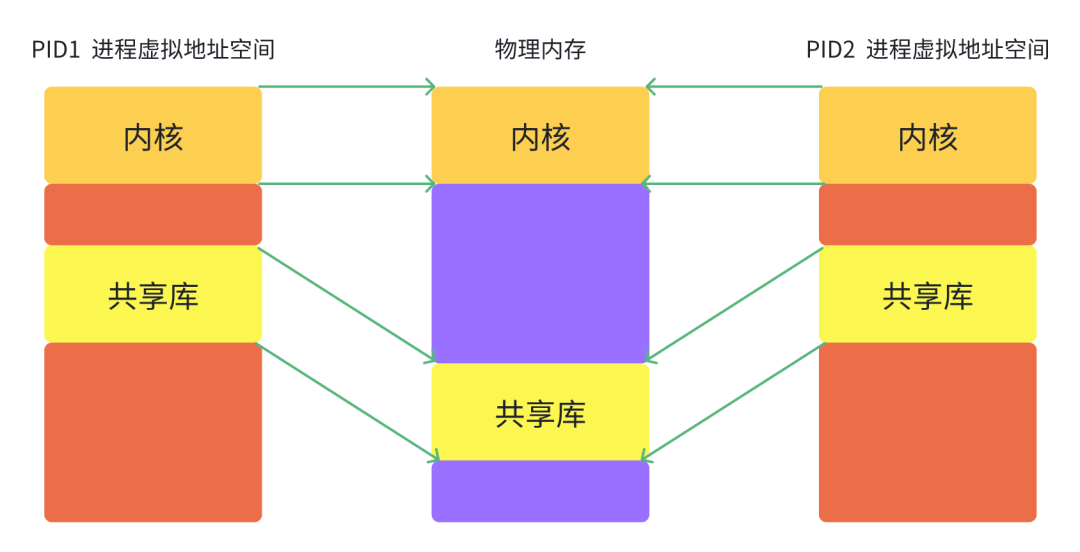
共享库的内存映射区域:共享库通常在物理内存中只存储一份,多个进程可以将同一份共享库的虚拟地址映射到相同的物理内存上。内核通过内存映射技术来实现这一点,以减少物理内存的浪费。不同进程的虚拟地址范围可能不同,但它们映射到相同的物理内存位置。 -
用户栈区域:用户栈区域是进程的栈空间,内核为每个进程分配一块虚拟地址范围作为栈。栈的管理由内核完成,包括栈的动态扩展和收缩。内核确保不同进程的栈不会相互干扰,通过为每个进程分配独立的虚拟地址范围。 -
内核区域:内核区域包含操作系统的代码、数据和栈空间。内核在物理内存中只存储一份,每个进程都将其虚拟地址映射到相同的物理内存上。不同进程之间的隔离是通过硬件内存保护机制和虚拟内存管理来实现的。
-
缺乏隔离性:每个进程都应该拥有独立的虚拟地址空间,以确保它们之间的隔离。直接访问物理地址会绕过虚拟内存管理,导致进程之间的干扰和冲突。这可能导致数据损坏、进程崩溃或整个系统不稳定。 -
安全问题:绕过虚拟内存管理的访问可以被滥用,可能导致安全漏洞。恶意代码可以尝试读取或修改其他进程或操作系统的敏感数据,这对系统的安全性构成威胁。 -
硬件保护机制:现代计算机系统使用硬件保护机制来防止进程直接访问物理地址。这些机制包括内存管理单元(MMU)和特权级别(例如,用户态和内核态)。绕过这些机制将触发硬件中断或异常,导致程序中止。 -
可移植性问题:直接访问物理地址的代码通常不具备可移植性。因为物理地址在不同的计算机系统上会有不同的映射,这样的代码无法在不同的系统上运行。
-
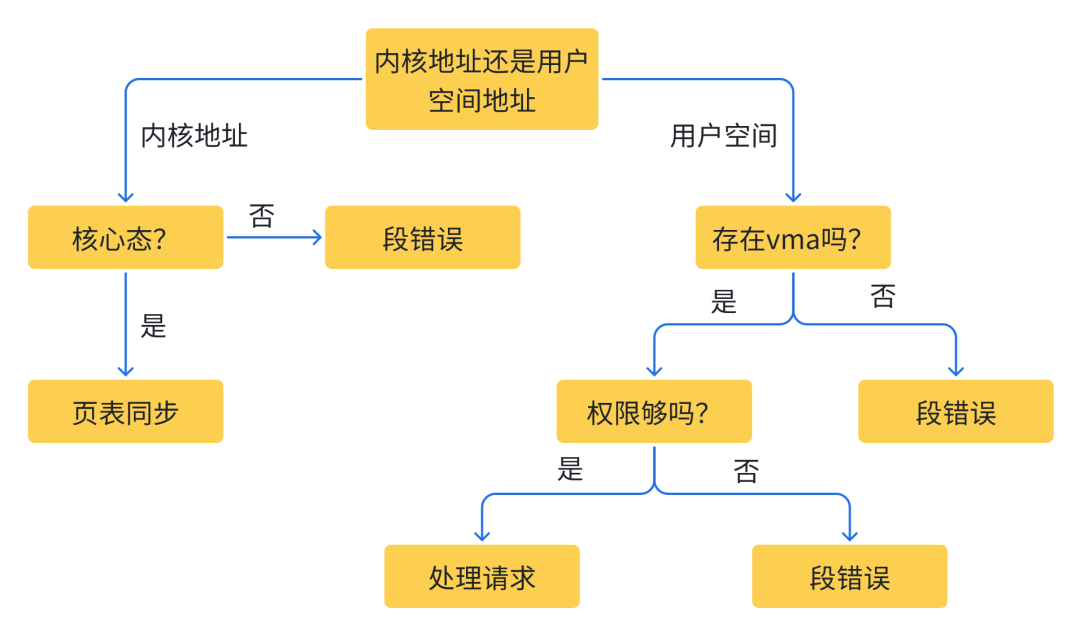
访问非法内存地址:段错误通常发生在尝试读取或写入未分配给程序的内存地址时。这可以包括访问空指针(null pointer)或已释放的内存。 -
内存越界访问:当程序尝试访问超出其分配内存范围的位置时,也会触发段错误。这通常发生在数组越界、缓冲区溢出或堆栈溢出的情况下。 -
访问只读内存:在某些情况下,尝试写入只读内存区域会触发段错误。例如,试图在字符串文字常量上执行写入操作。
SIGSEGV(Segmentation Violation)的信号。这个信号表明程序尝试执行了非法的内存操作。一旦发生段错误,通常会导致程序异常终止,除非程序员在代码中明确处理了这种情况。-
缺页异常触发:当用户程序尝试访问一个页面,但该页面不在当前进程的物理内存中时,会触发一个缺页异常。 -
中断处理程序:操作系统内核中有一个专门的中断处理程序(中断服务例程)来处理缺页中断。这个程序会被硬件中断控制器(如x86架构中的IDT)调用。 -
查找页面:中断处理程序首先会检查引发缺页的虚拟地址,以确定所需的页面。这个虚拟地址通常包括在异常的上下文中。内核会查找与该虚拟地址相关联的物理页面。 -
页面是否在内存中:如果所需的页面已经在物理内存中(缺页已经被解决),则不需要磁盘访问。中断处理程序会将页面映射到进程的地址空间,然后重新启动引发缺页异常的指令。 -
页面不在内存中:如果所需的页面不在物理内存中(缺页尚未解决),则需要从磁盘上的页面文件中读取页面数据。此时,Linux内核会启动一个页面调度程序(Page Scheduler),它负责将页面从磁盘加载到物理内存中。 -
磁盘I/O:页面调度程序会根据需要启动磁盘I/O操作,将页面数据从磁盘读取到物理内存中的空闲页框(Page Frame)中。这通常涉及到磁盘I/O调度、读取磁盘块、物理页帧分配等操作。 -
页面表更新:一旦页面数据加载到物理内存中,内核会更新页表,将虚拟地址映射到新加载的页面。这样,进程就可以访问所需的页面。 -
重新执行引发缺页的指令:完成页面加载和页表更新后,内核会重新执行引发缺页异常的指令,使进程能够正常访问所需的页面数据。 -
返回用户空间:处理完成后,控制权返回到用户空间的进程,继续执行。
-
中断或系统调用触发切换: -
进程切换通常是由硬件中断(如时钟中断)或进程主动发起的系统调用(如fork、execve)触发的。 -
当中断或系统调用发生时,CPU会进入内核态,即从用户态切换到内核态。
-
-
保存当前进程的上下文: -
在内核态中,首先需要保存当前运行进程的上下文信息。这包括寄存器的内容、程序计数器(PC)的值、堆栈指针(SP)的值等。 -
这些上下文信息通常保存在进程的内核栈中,以便在切换回该进程时能够恢复到之前的状态。
-
-
调度器选择下一个要运行的进程: -
内核的调度器会根据调度算法(如CFS、O(1)调度器)从就绪队列中选择下一个要运行的进程。 -
选择的依据可能包括进程的优先级、时间片等。
-
-
切换页表: -
每个进程都有自己的页表,用于虚拟地址到物理地址的映射。在进程切换时,需要切换页表以确保访问正确的物理地址。 -
Linux内核会更新CPU的页表基址寄存器(CR3寄存器),将其设置为新进程的页表基址。 -
这确保了CPU在访问内存时使用了正确的地址映射。
-
-
加载下一个进程的上下文: -
内核会加载下一个进程的上下文信息,将其寄存器值、程序计数器等恢复到CPU中。 -
这个步骤使CPU能够继续执行下一个进程的指令。
-
-
执行新进程: -
一旦新进程的上下文被加载并且页表被切换,CPU将继续执行新进程的代码。 -
这个进程切换过程就完成了,CPU现在运行的是新选择的进程。
-
-
地址映射:MMU负责将应用程序生成的逻辑地址(在程序中使用的地址)映射到物理地址(在计算机的实际硬件中存在的地址)。这个过程通常涉及到将逻辑地址的段(segment)或页(page)映射到物理内存中的对应段或页。 -
地址保护:MMU可以通过设置访问权限位来保护内存。例如,它可以标记某些内存区域为只读或禁止访问,以确保程序不会意外地修改关键数据或访问不允许的内存区域。 -
虚拟内存:MMU使操作系统能够实现虚拟内存的概念。虚拟内存允许每个进程认为自己拥有整个物理内存,而实际上,物理内存可能被多个进程共享。MMU负责将进程的虚拟地址映射到物理内存,以便多个进程能够同时运行而不会相互干扰。 -
缓存管理:现代CPU通常拥有多级缓存,MMU也可以参与缓存管理,确保缓存中的数据与主内存保持一致性。 -
TLB(Translation Lookaside Buffer):为了提高地址转换的速度,MMU通常包含一个TLB,它是一个高速缓存,存储了最近的地址映射信息。TLB能够快速查找逻辑地址到物理地址的映射,从而提高内存访问的速度。
-
保存当前进程的上下文:在切换进程之前,操作系统会保存当前进程的CPU寄存器状态和其他上下文信息。 -
加载新进程的页表:操作系统会加载新进程的页表基地址到MMU中,这意味着MMU将开始使用新进程的地址映射信息。 -
恢复新进程的上下文:操作系统会从新进程的上下文中恢复寄存器状态和其他信息。 -
切换完成:一旦上述步骤完成,CPU将继续执行新进程的指令。
mm_struct结构体中的pgd字段来访问的。在Linux内核中,mm_struct结构体存储了有关进程的内存管理信息,而pgd字段指向了页全局目录(Page Global Directory),用于页表的顶层地址转换。// 获取当前进程的mm_structstruct mm_struct *mm = current->mm;// 获取当前进程的页表基址(pgd)pgd_t *pgd_base = mm->pgd;
current是一个指向当前进程的task_struct的指针,可以通过#include <linux/sched.h>头文件访问。然后,通过current->mm来获取当前进程的mm_struct,再从中提取pgd字段,即页表基址。-
主机发送起始信号(Start Condition):主机产生一个低电平脉冲,表示通信开始。 -
主机发送从机地址:主机发送从机设备的7位地址(8位地址中的最高位是读/写位,由主机指定)。通常,从机设备的地址是唯一的。 -
主机发送读命令:主机发送一个读命令位,指示它希望从机设备将数据发送给它。 -
从机应答:如果从机设备存在并且其地址与主机发送的地址匹配,它将发送一个应答信号。 -
主机接收数据:主机接收从机设备发送的数据字节,这通常是8位。 -
主机发送应答或非应答:主机可以选择发送一个应答(ACK)信号,表示它希望从机设备继续发送更多数据,或者发送一个非应答(NACK)信号,表示它已经接收足够的数据或不希望继续接收。 -
重复读取或发送停止条件:如果主机希望继续读取更多数据,它将重复步骤4到步骤6。否则,它会发送一个停止条件(Stop Condition),表示通信结束。 -
从机释放总线:从机设备在通信结束后释放总线,以便其他设备可以访问总线。
-
连接示波器: -
将示波器探头的地线(黑色线)连接到电路板上的地。 -
将示波器探头的信号线(通常是红色线)连接到I2C总线上的SDA线。 -
将另一个示波器探头的信号线连接到I2C总线上的SCL线。
-
-
设置示波器: -
打开示波器并选择合适的通道来显示SDA和SCL信号。 -
设置示波器的时间基准,以便捕获足够的波形数据。 -
如果有必要,设置触发条件,以便示波器开始捕获波形数据。
-
-
开始捕获: -
启动示波器以开始捕获波形数据。 -
在启动I2C通信之前,确保示波器已经开始捕获。
-
-
观察波形: -
示波器将显示SDA和SCL信号的波形图。您可以看到时钟和数据信号的高低电平以及它们的时序。 -
根据I2C协议,分析SDA和SCL的时序以确定起始条件、地址、数据和停止条件。
-
-
分析波形: -
分析波形以确定每个I2C传输的开始和结束、地址、数据位以及应答信号。 -
注意波形中的任何错误或问题,例如丢失的应答或噪声。
-
-
停止捕获: -
停止示波器以结束波形数据的捕获。 -
可以查看和分析捕获的波形数据。
-
-
解码数据: -
使用捕获的波形数据,您可以解码I2C通信,识别读取和写入操作,并提取传输的数据。
-
// 双向链表节点定义struct Node {int data;Node* prev;Node* next;Node(int val) : data(val), prev(nullptr), next(nullptr) {}};// 在指定节点后插入新节点void insertAfter(Node* prevNode, int newData) {if (prevNode == nullptr) {std::cout << "Previous node cannot be null." << std::endl;return;}Node* newNode = new Node(newData);newNode->next = prevNode->next;newNode->prev = prevNode;if (prevNode->next != nullptr) {prevNode->next->prev = newNode;}prevNode->next = newNode;}// 打印链表void printList(Node* head) {Node* current = head;while (current != nullptr) {std::cout << current->data << " ";current = current->next;}std::cout << std::endl;}int main() {// 创建一个双向链表: 1 <-> 2 <-> 3Node* head = new Node(1);Node* second = new Node(2);Node* third = new Node(3);head->next = second;second->prev = head;second->next = third;third->prev = second;std::cout << "原始链表: ";printList(head);// 在第二个节点后插入新节点insertAfter(second, 4);std::cout << "插入后的链表: ";printList(head);return 0;}
大家都知道,海康并不是一个纯软件公司,所以能问上边这些问题都很正常。
正是秋招的好时候,大家一定要抓紧时间啊。有任何想了解或者迷茫的地方,可随时联系我,咱唠唠。